Three major issues:
Note: Two and three apply to threads just as much as
to processes! Number one doesn't, since threads share memory.
Important point: "No perfect scheme is known." --
Wikipedia
Picture a single-user bathroom with a door
on its north side and a door
on its south side. You want to enter by the north door,
while someone else wants to enter by the south one. You
both knock: no one answers.
So you both enter.
Oops! Embarrasment.
But in the case of processes, the result can be worse. Two
processes check to see if there is a seat left on a flight
to London. There is... one seat left. Both processes
get told "Yes." And now they each assign the seat... to
different passengers.
Oops! One of them is going to have to be given a lot
of bonus miles to give up their seat.
And this can get even worse: imagine the code is
determining if it is safe to place more uranium in the core
of a nuclear power plant, and two processes both get told
it is safe two put in one more unit... so they both
put in one more unit... and we have a terrible disaster.
This is not a mere hypothetical... race conditions in the
Therac-25
radiation therapy machine killed at least three
people. The
great Northeast blackout of 2003
was also caused by race conditions in software not being dealt
with properly.
Race conditions are made only more prevalent by multi-core CPUs, since more processes are actually running at once.
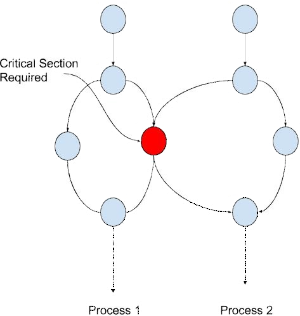
Four conditions for a good "critical region" solution:
Various possibilities for achieving mutual exclusion:
The CPU only switches among processes when an interrupt occurs. Therefore, if a process disables interrupts upon entering a critical region, there is no danger another process can interfere with what it is up to.
But what if a user process turns off interrupts, and
never turns them on again? The system is now dead!
Also, on a multi-CPU system, disabling interrupts only
affects one CPU: other CPUs can still access shared
memory.
On the other hand, it may be useful for the
kernel to disable interrupts: if it is updating
a critical table, it may be important that no process
can interrupt the update.
So: Disabling interrupts is OK inside the
kernel, but is not a useful way for user processes to
avoid race conditions.
Let's go back to the bathroom example to understand the
lock variable solution. This is like having the bathroom
doors bear a little sign that says in use. The person
who wants to use the restroom checks to see if the sign
says "in use." If it does not, the person enters the
room, And then sets the sign by locking both doors.
However, this does not solve the problem: both people
can show up, one at the south door and one at the north
door, both find the sign says "Vacant," and both enter
the room.
Busy waiting: Continually testing some condition
until it says "go ahead". Not very efficient.
Strict alternation violates condition three of our
desired conditions above: is the turn of process X to
enter its critical region, but it doesn't need to enter
that region at the moment, it nevertheless blocks
processes Y and Z entering their critical region.
Bathroom analogy: it is as though you can't go to the
bathroom when it is someone else's turn, even if
they don't need the bathroom!
A lock using busy waiting is called a spin lock.
Peterson's ingenious solution is to combine the turn idea with the idea of "being interested": so you go to use the loo (British for restroom). You register that you are interested, and then set turn to you. Whoever sets turn last wins, and gets to go in. But if no one else is interested, you always get to "go."
This solution solves the race condition problem by
creating a new, atomic instruction, TSL (test
and set lock), that means a process checking to see if
the bathroom is free can also set a lock on the door in
an uninterruptible operation.
Crucial point: All solutions depending upon
calls to enter_region and leave_region
depend upon processes not cheating and simply entering
their critical region without making the proper calls!
XCHG is a similar instruction, now available on Intel
processors.
A problem with Peterson, TCL, and XCHG: they all involve
busy waiting.
Bathroom analogy: you stand at the bathroom door,
repeatedly knocking once every microsecond.
This not only wastes CPU time, but can create priority
inversion problems: a high-priority process is
looping, waiting to enter its critical region, and a low-
priority process is ready to leave its critical region.
But the high-priority process never yields to the lower
one, and so it loops forever!
Mars Pathfinder priority inversion problem
We can use a sleep and wakeup pair of calls
to avoid busy waiting.
The situation: Once process listens on a socket and produces stock quotes, putting them in a buffer. Another process consumes stock quotes, removing them from the buffer.
We can still get race conditions with these calls: the
consumer could check the number of items in the buffer
and finds it to be 0, but before it can go to sleep, the
producer is scheduled, and begins filling the buffer.
The producer repeatedly calls wakeup on the
consumer, but the consumer has not gone to sleep!
Finally, the producer fills the buffer, and goes to
sleep. The consumer is activated, finds the buffer size
(it held from long ago) is 0, and goes to sleep.
Everyone is asleep!
The soltion is to make the operations of checking the
relevant variable, and then re-setting it or going to
sleep, atomic.

The key to semaphores is that they are implemented as
atomic operations at the OS level. That means that
all of the operations in the semaphore complete as a
unit, with no possibility of interruption.
Below is code for semaphores: if either up() or
down() is entered, it is guaranteed to complete
without interruption.
down(sem s) {
if (s > 0)
s = s - 1;
else
/* put the thread to sleep on event s */
}
up (sem s) {
if (one or more threads are waiting on s)
/* wake up one of the threads sleeping on s */
else
s = s + 1;
}
(Code from: https://www.cs.rutgers.edu/~pxk/416/notes/06-sync.html)
Here is the Tanenbaum-Bos code for solving the producer-consumer problem using semaphores:
#define N 100 /* number of slots in buffer */
typedef int sem; /* a special sort of int */
sem mutex = 1; /* for mutual exclusion */
sem empty = N; /* keep producer from over-producing */
sem full = 0; /* keep consumer sleeping if nothing to consume */
void producer() {
int item;
while (TRUE) {
item = produce_item(); /* produce something */
down(&empty); /* decrement empty count */
down(&mutex); /* start critical section */
insert_item(item); /* put item in buffer */
up(&mutex); /* end critical section */
up(&full); /* +1 full slot */
}
}
void consumer() {
int item;
while (TRUE) {
down(&full); /* one less item */
down(&mutex); /* start critical section */
remove_item(item); /* get the item from the buffer */
up(&mutex); /* end critical section */
up(&empty); /* one more empty slot */
consume_item(item); /* consume it */
}
}
A mutex is a binary semaphore, short for mutual exclusion.
Spin locks are OK if the wait is short, but bad if not.
So block the process!
But if there is little contention, this creates to many
switches to kernel mode.
So, how about futexes: they are a Linux feature,
short for "fast user space mutex." A thread grabs a
lock, and if the lock is free, just proceeds with no
kernel-mode switch. Only if the lock was not free it
performs a system call to put the thread on the queue
in the kernel.
Pthreads is short for POSIX threads, and they are implemented by a set of types, functions and constants in the C programming language. The standard supports mutexes, condition variables, and the possibility of busy waiting.
Monitors are a feature of a programming language created to
make synchronization easier. Languages with monitors
include Java, C#, Visual Basic, and Ada.
Below is code showing the use of monitors in Java: it is
the synchronized keyword that creates the monitor.
class producer_consumer {
private boolean item_ready = false;
public synchronized int produce_item() {
while (item_ready == true) {
try {
wait(); // block until signaled (notify)
} catch (InterruptedException e) { } // ignore
}
item_ready = true;
// generate the item
notify(); // signal the monitor
return item;
}
public synchronized void consume_item(int item) {
while (item_ready == false) {
try {
wait(); // block until notified
} catch (Interrupted Exception e) { } // ignore
}
// consume the item
item_ready = false;
notify(); // signal the monitor
}
}
(Code from: https://www.cs.rutgers.edu/~pxk/416/notes/06-sync.html)
Message passing uses system calls like:
send(destination, &message)
and
receive(source, &message)
The calls could block, or could return with an error
code. The process might busy-wait.
Main isues:
We use mailboxes as a buffer.
Or we could have no buffer, and block when there is no
message, or until the message is received.
A barrier is a way to ensure, for example, that the
repeated computation of a very large matrix, distributed
across many processors, completely finishes iteration
n before iteration n + 1 kicks off.
The idea is all processes need to reach the barrier before
any go to the next phase.
Usually we can't let multiple process "have at" a data
structure at the same time. We can't have one process sort
records while another averages them.
But sometimes it makes sense to let:
One writer; and
Multiple readers
access some data.
Readers get a copy of the data. The writer updates the data
privately, then the new, "fixed up" version is put back in
a single operation. Later readers only see the new version.
No one sees an intermediate one.