| Notation | Intuition | Definition |
|---|---|---|
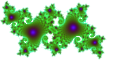
| g(n) = O(f(n)) | g is bounded above by f (up to constant factor) asymptotically | g(n) ≤ k*f(n) for some positive k, after some n |
| Notation | Intuition | Definition |
|---|---|---|
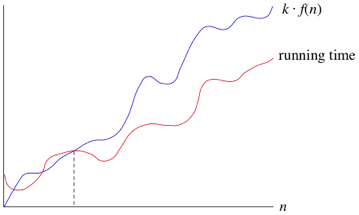
| g(n) = Θ(f(n)) | g is bounded above and below by f asymptotically | k2*f(n) ≤ g(n) ≤ k2*f(n) for some positive k1, k2 |
| Notation | Intuition | Definition |
|---|---|---|
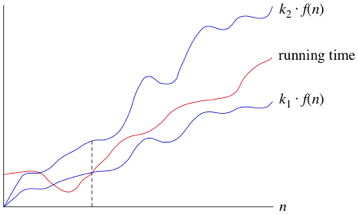
| g(n) = Ω(f(n)) | g is bounded below by f asymptotically | g(n) ≥ k*f(n) for some positive k |
| Notation | Intuition | Definition |
|---|---|---|
| g(n) = o(f(n)) | g is dominated by f asymptotically | g(n) < k*f(n) for every positive k |
| Notation | Intuition | Definition |
|---|---|---|
| g(n) = ω(f(n)) | g dominates f asymptotically | g(n) > k*f(n) for every positive k |
Why not just Big-Θ?
From the Khan Academy site:
We use big-Θ notation to asymptotically bound the growth of a running time to within constant factors above and below. Sometimes we want to bound from only above. For example, although the worst-case running time of binary search is Θ(lg n), it would be incorrect to say that binary search runs in Θ(lg n) time in all cases. What if we find the target value upon the first guess? Then it runs in Θ(1) time. The running time of binary search is never worse than Θ(lg n), but it's sometimes better. It would be convenient to have a form of asymptotic notation that means "the running time grows at most this much, but it could grow more slowly." We use "big-O" notation for just such occasions.
Graphs and a table on why we only care about the highest-order

| n |
Fast Alpha machine,
C code, running O(n3) algo. |
TRS-80
interpreted Basic, running O(n) algo. |
|---|---|---|
| 10 | .6 microsecs. | 200 millisecs. |
| 100 | .6 millisecs. | 2 secs. |
| 1000 | .6 secs. | 20 secs. |
| 10,000 | 10 mins. | 3.2 mins. |
| 100,000 | 7 days | 32 mins. |
| 1,000,000 | 19 years | 5.4 hours |
(Table from Jon Bentley, Programming Pearls.)
The textbook uses lg for base-2 logarithms. But... the base doesn't really matter! Why?
| n | log base-2 | log base-10 | Differ by... |
|---|---|---|---|
| 2 | 1 | .301 | 3.322 |
| 10 | 3.322 | 1 | 3.322 |
| 32 | 5 | 1.505 | 3.322 |
They differ by a constant factor!
Log rule: logb(x)
= logc(x)
/ logc(b)
So...
log10(32)
= log2(32)
/ log2(10)
= 5 / 3.322 = 1.505
Also, let's look at logs versus polynomial growth. Even for very small powers p > 0, xp grows faster than log x. Below we use natural logs:
| p | xp > log x at |
|---|---|
| .3 | 379 |
| .2 | 332,105 |
| .1 | 3,430,631,121,407,801 |
Let's say we posit a search operating in 2n + 3 time.
We want to show that this has Θ(n) complexity.
We must find k1, k2,
and n0, so that:
k1 * n < 2n + 3 < k2 * n
One solution is k1 = 1,
k2 = 3,
and n0 = 4.
The problem of computing, given n ≥ 0, the nth Fibonacci number Fn.
The Fibonacci discussion is not in the textbook. One place where it is presented in a nice way similar to what I will do in class is in section 0.2 of the DasGupta, Papadimitriou, Vazirani Algorithms book.
Talked about the obvious recursive algorithm; how it is very slow, intuitively due to recomputing the same subproblems. Proved that the recursion tree grows at least as fast as the Fibonacci sequence itself.
Note that every leaf of the recursion tree returns one. The sum of the value of all of these leaves is going to be the Fibonacci number we return. Therefore, there must be at least as many operations as the Fibonacci number itself.
Showed how to speed the recursive algorithm algorithm up by "memoization": Using a table to store answers for subproblems already computed. Analyzed the running time and space of the recursive memoized version and of the iterative algorithm that fills the table going in the forward direction. Pointed out how to reduce space to constant.
Naive and faster Fibonacci code.
By the way, this is an open-source project: you may contribute!
There is a closed-form formula for computing Fibonacci numbers.
So why can't we claim we can compute nth Fibonacci number in constant time? Did not go into details, but this is related to our inability to directly represent irrational numbers such as square roots, maybe related to precision/rounding, and generally related to what operations are allowed and what are not, in an algorithm.
Using some tricks one can construct nth Fibonacci number in O(log n) arithmetic operations, where we count additions/subtractions/multiplications and do not worry about the fact that eventually the numbers get too large to manipulate in constant time.
Data structures form a very important part of algorithmic research.
However, this course does not focus on data structures. We will only devote a couple of lectures, total, to this subject. (There are algorithms courses that spend their entire time on data structures. We have an advanced data structures expert in the department, Prof. John Iacono.)




sum = 0;
for (int i = 0; i < n; i++)
for (j = 1; j < n; j = j * 2)
sum += n;
void complex(int n)
{
int i, j;
for(i = 1; i < n; i++) {
for(j = 1; j < log(i); j++)
}
printf("Algorithms");
}
void complex(int n)
{
int i;
for(i = n; i > 1; i = i/2){
printf("Algorithms")
}
}