
Operations associated with this data type allow:
(Source)
Typical uses:
Direct addressing and Hashing are two ways of implementing a dictionary. Are there others?
Direct-Address-Search(T, k)
return T[k]
Direct-Address-Insert(T, x)
T[x.key] = x
Direct-Address-Delete(T, x)
T[x.key] = NIL
1. a; 2. a; 3. b;

What happens to the usual assumptions?
Correctness: always, most of the time?
Termination: always, or almost always?
What does "performance" mean if the running
time/answer/even termination change from one run to the next?
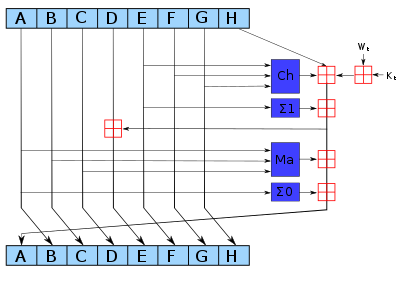
This employs chaining. Furthermore, we assume that the
distribution of elements is uniform across hash table slots.

Consider the following hashing scheme:
h(k) = k mod m
m = 7
We convert a string into a hashable key by treating it as a
base-8 number.
So 'abc', where a = 1, b = 2, and c = 3, is converted to a
key as follows: 1 * 82 + 2 * 8 + 3 = 83.
In this hashing scheme, what do the strings 'cba' and 'bac'
hash to?
Can you write a more general statement about a pattern we
can detect here? Something along the lines of, "If the table
size is 2P - 1, and strings
are interpreted in radix 2P..."
Answer:
If h(k) = k mod m,
where m = 2P
− 1, and k is a
character string interpreted in
radix 2P, then all
permutations of a given string
will hash to the same value. So in the example above, 'abc',
'cba', and 'bac' all hash to the same value.
Proof:
Assumed (could be proven, but we won't do it here):
So, we have:
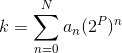
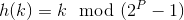
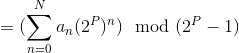
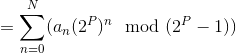 (By 1)
(By 1)
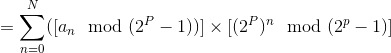 (By 2)
(By 2)
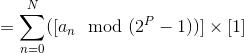 (By 3)
(By 3)

We can get even better perfromance with a fixed hash table --
think of reserved words in a programming language, or the
index of a CD -- by perfect hashing.
We proceed as in hashing with chaining, but then, instead of a
linked list, each hash slot gets a hash table
mj of size n2, where
n is the number of elements expected to hash to slot
j.
The probability of geetting a collision is much like the
birthday problem: when the table size is the square of the
expected number of entries, the probability of collisions
is < 1/2. So we can just try hash functions until we find
one that produces no collisions.